





















The explosion of data generated by businesses has led to an increasing demand for efficient and precise methods of analysis for informed decision-making. Data pipelines serve as a solution to this need by providing a streamlined process for collecting, transforming, and analyzing data.
At their core, data pipelines serve to move data from its source to a destination, such as a data warehouse, for analysis and storage. They are the backbone of modern data-driven organizations, providing a way to automate data flow and ensure consistency in data processing.
In this article, we will provide an in-depth review of data pipelines, including their architecture and various use cases across different industries. By the end of this article, you will have a thorough understanding of how data pipelines work and where you can utilize them in your organization.
Let’s get started.
What Is A Data Pipeline?


A data pipeline is a method used to move raw data from its source to a destination for analysis and storage, and it automates and optimizes the whole process of data gathering, analysis, and storage. Data pipelines are used for a variety of purposes, including data acquisition, transformation, cleaning, enrichment, aggregation, and storage.
- Data acquisition involves bringing data from various sources, such as databases, into the pipeline.
- Data transformation involves changing the structure of the data, like converting unstructured data into structured data or vice versa.
- Data cleaning involves removing duplicates and other unnecessary information from the dataset.
- Data enrichment involves adding additional information to the dataset, such as adding geographic information to customer data to enable location-based marketing campaigns.
- Data aggregation involves grouping records together for analysis, like collecting and consolidating information from multiple social media platforms.
- Finally, data storage involves storing data in a format that enables retrieval and distribution to authorized parties at a later time.
What Are Data Pipeline Architectures?
Not all data pipelines are made the same. Their architecture defines the implementation of the processes and tools and how they are used to move data within the pipeline. Data pipeline architecture can be applied using various tools and technologies, including open-source frameworks, commercial solutions, or a combination of both.
Ultimately, the choice of tools and technologies will depend on the specific requirements and constraints of the data pipeline being designed. Some of these technologies are:
A. Extract, Transform, Load (ETL) tools
These tools are designed specifically to extract data from various sources, transform it into a standardized format, and load it into destinations such as data warehouses or data lakes. Examples of ETL tools include Talend, Estuary, and Apache Nifi.
B. Data Ingestion Tools
These tools are used to ingest data in real-time from various sources such as sensors, logs, and social media platforms. Examples of data ingestion tools include Estuary, Apache Kafka, and Amazon Kinesis.
C. Data Processing Engines
These engines are used to process data in batch or stream mode, depending on the needs of the pipeline. Examples of data processing engines include Apache Spark and Apache Flink.
D. Data Storage And Retrieval Systems
These systems are used to store and retrieve data in a structured or unstructured format. Examples include relational databases (such as MySQL and Oracle), NoSQL databases (such as MongoDB and Cassandra), and data lakes (such as Amazon S3 and Azure Data Lake).
E. Monitoring And Management Tools
These tools are used to monitor and manage the data pipeline, including tracking the status of jobs, debugging errors, and monitoring performance. Examples include Apache Ambari and Datadog.
Want to know more about data pipeline architectures? Click here to find out.
7 Amazing Use Cases To Understand & Leverage The Power Of Data Pipelines
Let’s now explore seven data pipeline use cases across a range of industries.
1. AI And Machine Learning Data Pipelines


With all the buzz going on around AI these days, the need for optimizing the deployment of AI applications is increasing rapidly. This is where Machine Learning pipelines can help. ML pipelines streamline the deployment of AI applications by optimizing and automating the steps that data goes through to be transformed and analyzed by a model.
But why are Machine Learning pipelines so important?
Think about a typical machine learning workflow. In traditional AI system design, all ML workflow tasks are scripted and completed in a sequence. But this approach becomes a problem as the system scales.
For example, deploying multiple versions of the same model using traditional methods involves rerunning the entire operation including data ingestion and processing multiple times.
Machine Learning pipelines solve this issue by breaking down the workflow into modular services. When creating a new version, you can select which components to use and any changes to a service to apply globally.
There are many tools available for building ML pipelines, including open-source options like TensorFlow and Scikit-learn and commercial products like DataRobot, H2O.ai, and Big Panda
To help streamline machine learning workflows, these tools have features like:
- Data ingestion
- Preprocessing
- Model training
- Evaluation
- Deployment
- Monitoring
So the next time you’re debating the meaning of life with ChapGPT, just remember that a Machine Learning pipeline was probably involved in making it all happen.
2. Big Data Pipelines


You’ve probably heard the term “big data” floating around a lot lately, and for good reason. There’s a ton of data generated all the time and it’s only going to keep growing. According to IDC, the global data sphere is set to reach 163 zettabytes by 2025. That’s a lot of zeros.
And with all of this data comes a lot of potential for businesses to turn it into valuable insights and drive growth. But with the sheer volume of data out there, companies need to have a system in place for efficiently managing, processing, and analyzing it.
That’s where big data pipelines come in. They’re kind of like the superhighways of the data world. They move large amounts of data from various sources to a destination like a data warehouse or data lake. And unlike regular pipelines that just transport raw materials, these pipelines transform and optimize the data, making it easier to get valuable insights.
So, what makes big data pipelines different from other types of data pipelines?
For one, they’re built to manage massive amounts of data, often measured in terabytes or petabytes. As a result, they are suitable for processing and analyzing data from a variety of sources, including CRMs, IoT devices, and enterprise event logs.
Open-source choices like Apache Nifi and proprietary data pipeline tools like Estuary are only two examples of the many tools that can be utilized to build a big data pipeline.
The most important thing is to pick a tool that can scale with your demands, is reliable, and is simple to operate. By building a strong big data pipeline, you’ll unlock the full potential of your data and make more informed business decisions.
3. Data Pipelines For Social Media Platforms


Social media platforms like Twitter and Facebook have become an integral part of our daily lives, with billions of users generating massive amounts of data every day. But it’s not just about sharing memes and catching up with friends – these platforms have also become major players in the world of business and advertising.
With billions of dollars at stake, these platforms must have efficient data pipelines to collect, store, and analyze the data generated by users. Every post, like, comment, and share creates a wealth of information that needs to be collected, stored, and analyzed in real-time. Data pipelines step in at this point.
Data pipelines are the behind-the-scenes heroes of social media, responsible for managing the data generated by users. They enable the analysis of user behavior and trends, the detection and response to emergencies, and the enforcement of policies and regulations.
But data pipelines do more than just help us stay informed about emergencies. They can also be used to analyze user behavior and preferences, and improve the user experience.
So how do social media platforms build their data pipelines?
It’s not an easy task, given the high volume and variety of user data and social media’s real-time nature. Both Twitter and Facebook use a combination of internal tools and external technologies to build their data pipelines.
For example, Twitter relies on multiple tools:
- Heron for streaming
- Scalding for batch processing
- TSAR for both batch and real-time processing
- Data Access Layer for data discovery and consumption
On the other hand, Facebook uses Scribe as a persistent, distributed messaging system for collecting and aggregating data, and Puma, Stylus, and Swift for stream processing.
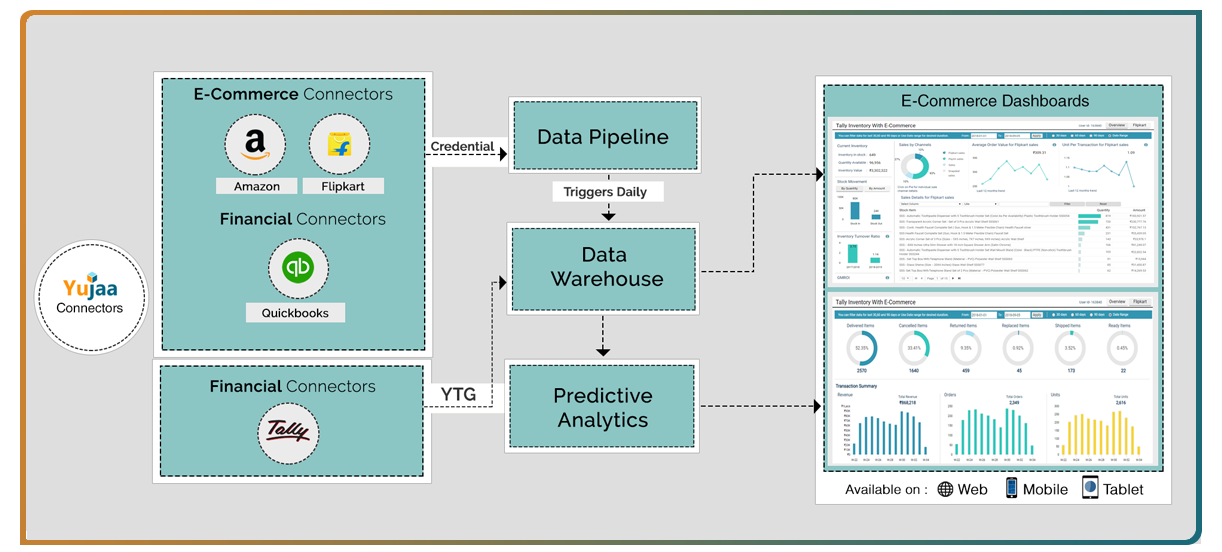
4. eCommerce Data Pipelines


Do you remember those spot-on product recommendations Amazon made for you the last time you were shopping on the site? They probably seemed like they knew you so well, right? Well, that’s likely because of all the data they record about your browsing habits and purchases.
eCommerce is a rapidly growing industry, with online sales projected to reach 25% of the total retail market by the end of 2026. With such a large financial stake in the game, eCommerce businesses must have efficient and effective ways of managing and analyzing their data.
And eCommerce businesses utilize all this data in several different ways. With it, they can:
- Optimize pricing
- Make product recommendations
- Personalize the user experience
- Process batch transactions quickly
- Forecast future demand for products
- Analyze their platform to improve its performance
- Improve the efficiency and effectiveness of marketing campaigns
eCommerce data pipelines are an important mechanism for managing the flow of orders and data, and they are critical to the success of these online businesses. Businesses can save time, money, and resources by automating and streamlining data processes through a data pipeline while gaining valuable insights into their operations.
5. Data Pipelines For Game Analytics
Gaming is expected to become a US$221 billion industry in 2023 and game analytics is an important part of the gaming industry’s success. It allows game studios to obtain important insights into player engagement by tracking key performance indicators, which in turn improves revenue generation.
With the growing popularity of gaming and the large amount of data created by players, it is becoming increasingly important for gaming companies to have a comprehensive and efficient data pipeline in place to efficiently utilize this data.
What makes game analytics data pipelines different from other pipelines is their extremely low latency and high scalability. Data pipelines for game analytics platforms are designed to handle the large volume of data generated by players in real time.
Players anticipate prompt feedback in a game and any delay in processing data might ruin the user experience. Moreover, the number of players and events can fluctuate dramatically over time, necessitating a pipeline that can handle abrupt surges in traffic.
There are several applications for these data pipelines. Tracking player activity and identifying patterns that can be used to optimize the game design or monetization strategy is a primary use case. Data on player retention and in-game purchases, for example, could help game designers learn what motivates players to continue playing and what difficulties they encounter.
Another application is to track the game’s performance in real-time and uncover problems that may degrade the user experience. This can include tracking server performance, identifying bugs, and monitoring in-game economy balances.
So what does this mean for you?
If you’re in the gaming industry, you should think about building a data pipeline to get the most out of your player data. It can make a big difference in terms of optimizing your game design and monetization strategies, as well as improving the player experience.
6. Data Pipeline For Healthcare Facilities


The healthcare industry is on the rise and with it, the importance of data in patient care and treatment. It’s unbelievable how much data is being generated from a plethora of connected medical devices and clinical systems today, and it’s only going to increase.
But it’s not just about the sheer amount of data being produced – it’s also about making sure that medical data is processed and used in a responsible way that benefits patients. And data pipelines help achieve this.
But do data pipelines for healthcare systems require anything special?
Yes, actually. There are a few design aspects of healthcare data pipelines that differentiate them from other pipelines. Firstly, data privacy is a top priority in healthcare systems. So a streaming data pipeline in healthcare systems needs to prioritize data governance and security to protect patient privacy.
Second, healthcare data can be generated from various sources, including electronic medical records, connected medical devices, and various third-party systems. Therefore, healthcare data pipelines must have data integration capabilities.
In addition, the need for redundancy and zero errors in healthcare data management makes efficient data pipelines essential for ensuring the integrity and reliability of the data used.
But data pipelines in healthcare aren’t just about moving data from point A to point B. They can also help:
- Reduce costs
- Improve patient outcomes
- Optimize healthcare operations
7. Data Pipeline For Autonomous Driving Systems


As we move into the future, autonomous driving technology is poised to transform the way we travel and interact with our environment. The financial and human impact of autonomous driving might be substantial, with the potential to significantly cut the number of traffic accidents, reduce fuel consumption, and boost mobility for individuals who cannot drive.
To make autonomous driving a reality, accurate data is essential to ensure the safety of passengers and other road users. The consequences of errors in this data could be devastating which makes it even more crucial that we put systems in place to ensure the reliability and accuracy of the data used to power these vehicles.
But what is the role of data pipelines in autonomous driving and what are the requirements from a performance standpoint?
In the case of autonomous driving, data pipelines collect, analyze, and interpret data from a wide variety of onboard sensors including LIDAR, cameras, GPS, and other sensors. This helps monitor the performance of critical systems such as motors and battery packs.
There are a few key differences between data pipelines for autonomous driving and other types of pipelines. Some of these are:
- Sheer volume and variety of data that must be processed: Autonomous vehicles generate vast amounts of data from a wide range of sources, including sensor data, GPS data, and other onboard systems data.
- High levels of reliability and robustness required: Another key factor to consider when designing data pipelines for autonomous driving is the need for high levels of reliability and robustness. Autonomous vehicles operate in complex and dynamic environments and even minor errors in the data pipeline can have serious consequences.
- Need for real-time processing: As the data generated by autonomous vehicles must be analyzed and interpreted in real-time to inform the vehicle’s decision-making process, real-time processing with very low latency is needed in these systems.
- Need for scalability: As the volume of data generated by autonomous vehicles is likely to increase significantly over time, data pipelines for these systems must be scalable.
Overall, data pipelines play a critical role in the operation of autonomous driving systems. These pipelines collect, process, and interpret data in real time to help the vehicle make decisions. As self-driving cars get better, data pipelines for them must also be improved to cater to the growing demand for data processing.
Conclusion
Data pipelines are critical tools for handling and analyzing massive amounts of data. They enable businesses to automate and streamline the process of transferring data from its source to a destination for analysis and storage, saving time and resources while getting valuable insights into their operations.
We discussed different data pipeline examples and saw how various industries, from healthcare to gaming, are using them to make data-driven decisions and stay ahead of the competition. To gain a similar competitive edge, Estuary’s powerful and easy-to-use platform can help you handle your data pipeline needs more efficiently.
Don’t miss this opportunity to streamline your data process, try Estuary today and see the difference it can make for your business. Continue reading the Estuary Blog to learn more about data engineering and how it can benefit your organization.



Popular Articles










{kind=link}